S1E4 到底多少个错误码才是合理的?
对外开放 OpenAPI 的时候,错误的设计也是一个极为影响开发者开发体验的设计点。今天我们简单聊聊关于错误码和错误处理
为什么需要错误码?
由于我们不能保证系统可以完全处理用户的请求,因此我们需要通过错误码来告诉开发者发生了不符合预期的情况。不符合预期的情况可能由用户输入错误导致,也可能由内部微服务故障导致。为了建设一个健壮(Robust)的系统,我们需要通过对外暴露一批错误码,帮助开发者更好地处理各种异常情况。
避免错误码数量过少
既然我们的目的是帮助开发者解决异常情况,那么一个合理的答案是:和异常情况匹配的错误码数量是一个好的错误码数量。
如果在某个 API 接口上提供了一个错误码,则意味着我们认为这个接口只会出现一种情况导致的错误。而实际上,很可能会有多种情况导致错误发生。这种情况经常在 OpenAPI 评审过程中被提出来,也是用户在使用 OpenAPI 时常遇到的问题:为什么我找不到这个错误码?对于开发者来说,无论输入何种错误,都会得到相同的错误码,难以定位和解决问题。同一个错误码也意味着你无法提供足够的错误信息来进行排查。例如,常见的 “400 Bad Request” 错误,如果参数很多,排查错误可能是一个极其痛苦的过程。
避免错误码数量过多
另一方面,错误码数量过多也会导致问题。有些 OpenAPI 接口提供了几十个不同的错误码,看起来感觉很不错。但是仔细一看,就会发现这些错误码实际上只是针对不同的字段错误而已,导致错误码数量快速增长。而实际上,可以将参数错误放在同一个错误码中,并通过动态的参数和原因来解决,而不是返回一堆类似的错误码。大量的错误码对于开发者来说,存在记忆困难的问题,在实际编写代码的过程中,也需要编写大量的错误处理逻辑,来兼容我们对外抛出的错误处理逻辑。
换一种思路来组织错误码
如果你无法很好的掌握拆分和组织错误码的粒度,那我可以给你一个建议:按照用户处理错误的手段来拆分错误码。过去从内部视角来组织和错误码,很容易出现错误码过多或过少的情况,而从外部视角来梳理错误码,则可以帮助我们更好的厘清错误码的分类和组织。
用户并不关注我们的系统到底因为什么出现了错误,他们只关心出现了什么样的错误?我应该如何处理这些错误?那错误码可以非常快速的收敛为以下几类:
- 本资源参数校验错误,对应的处理策略往往是开发者需要查看文档,了解资源参数的限制, 修改参数重新调用。
- 跨资源参数校验错误,对应的处理策略往往是开发者需要通过其他 API 获取关连资源的 ID 等信息,以便于重新调用。
- 请求频率太高,对应的处理策略是优化调用的接口和方法,调低并发量。
- 服务端错误,对应的处理策略是重试,并在重试无效时联系官方人员。
通过上述的分类方式,我们可以快速的将错误码归类到几个大的分类,从而实现合并同类项,收敛错误码但不至于让开发者不知道下一步 Action 的情况。
错误码不重要,错误处理才重要
看到这里,相信你对于文章中提出的什么才是好的错误码设计已经有了答案。但我想说的是,错误码从来都不是核心。实际上,如果我们回看各种编程语言的范式,大多没有错误码这种设计,而是选择将更多的信息通过 exception 这样的形式暴露给开发者。错误码的设计虽然给到开发者一个可以用来做唯一判定的数据,但可以做唯一判定的不一定非要是数字。数字错误码的设计严格来说,并不是一个好的设计,因为他使得你的代码中必然会存在某些特定的 Magic Number,你需要小心的维护这些 Magic Number 来确保向开发者返回错误时不至于返回错误的错误类型和错误码。
对于一个已经存在的 OpenAPI 系统来说,错误码已经成为既定事实,则要做的是让这套系统可以更好的运转下来。但如果你要设计一套全新的错误系统,那么类似 Slack 这样的返回形式,可能是一个更好的选择,既可以规避掉 Magic Number 的问题,又可以确保每一个错误有其对应唯一的枚举值。
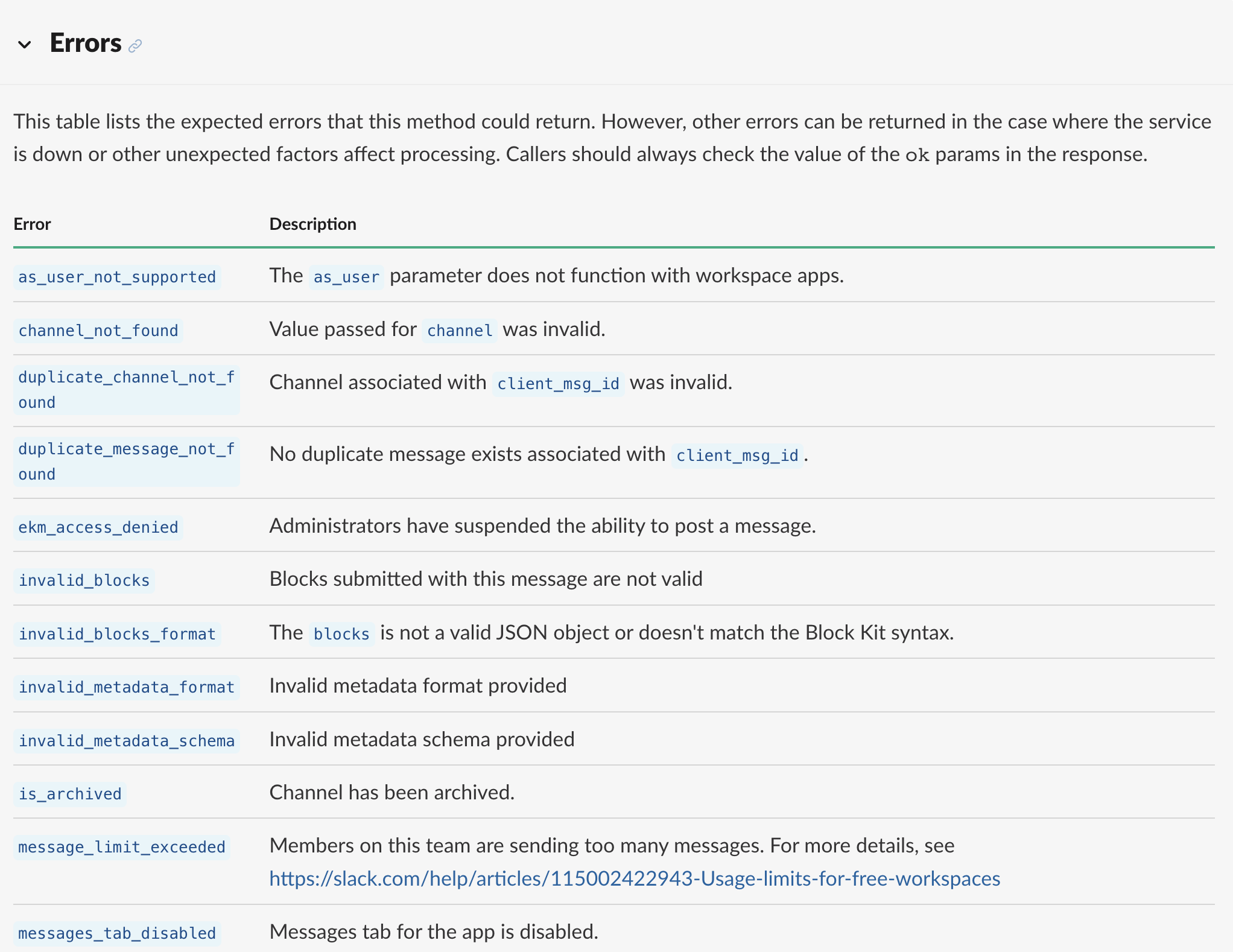
Slack 的 错误码设计
总结
好的错误码设计是适度的,你需要学会平衡错误码和对应错误信息的数量,不要太多干扰开发者,但也不可太少,不足以支撑实际的接口调用。好的错误码可以帮助我们和开发者建设更加健壮的系统,减少不必要的沟通成本,也可以让我们每一个使用这个 API 的人,都更加的幸福。